Introducing Parrot: The Fastest, Most Accurate Speech-to-Text Built for Voice Agents
Build real-time voice AI agents with Parrot, Ringg’s speech-to-text API. Transcribe Hindi-heavy calls with low latency, clean output, and production-grade accuracy.

Key Takeaways
Parrot is Ringg AI's native speech-to-text model built for real-time voice agents and production call workflows.
- It is optimized for low latency, clean LLM-ready transcripts, and Hindi-heavy or code-mixed customer conversations.
- The model is benchmarked against open-source Hindi datasets and built from Ringg's high-volume voice-agent production patterns.
- Teams can try Parrot through the Ringg dashboard or use the RinggLabs Python SDK.

Parrot is Ringg's native speech-to-text model for teams building real time voice applications. It is designed to turn live customer speech into clean, low-latency text that a voice agent can act on reliably.
For voice agents, STT is not a standalone transcription feature. It is the first layer of the agent's decision making system. If the transcript changes an address, delays final text, or formats an identifier inconsistently, the next API call or workflow can fail.
Ringg processes 1Mn+ minutes every month. Parrot was built from the production patterns that show up at that scale: compressed phone audio, code-mixed speech, and entity-heavy conversations where delay is immediately felt.
On open-source Hindi benchmark datasets, Parrot records 7.27 overall normalised WER, compared with 8.94 for ElevenLabs and 12.36 for Deepgram.
Contact us for early access to Parrot today, or you can immediately try out all the features in our API Playground!
Why Voice Agents Need Better Speech-to-Text
Most STT systems are still evaluated like transcription tools: clean files in, text out. Production voice agents need a different standard.
A voice agent does not simply display a transcript. It uses that transcript to decide what to do next: fetch an order, book an appointment, verify an identity, or trigger an API. A small STT error can therefore become a product error.
That changes the evaluation criteria. The important questions are not only "How accurate is the transcript?" but also:
- Is the final transcript ready fast enough for natural turn-taking?
- Are names, addresses, and domain terms preserved?
- Is the output clean enough for an LLM to consume directly?
- Does the pricing model scale with useful transcript output, not just audio overhead?
Parrot is built around those constraints.
What Parrot Optimizes For: Accuracy, Latency, and Clean Output
Parrot focuses on three outcomes that matter most in production voice AI:
Accuracy on Real Conversations
Word Error Rate (WER) is still a useful metric, but only when the test set reflects the audio you expect in production. Parrot is trained and evaluated on Hindi heavy, noisy calls, Indian accents, and domain-specific terms that regularly appear in enterprise workflows.
The model is designed to handle examples like:
- "अभी तो I am taking hydroxychloroquine sulfate"
- "मेरा order ID RGG 29481 है"
These are not edge cases in India. They are normal conversations.
Low Latency for Live Voice Agents
In a live voice agent, latency compounds across every user turn. A few hundred milliseconds added to each STT response can make the agent feel hesitant, increase total call duration, and reduce completion rates.
Our team has reduced this compute latency to approximately 60 ms in internal tests, compared with the 100-150 ms range we observed from other vendors under comparable streaming conditions.
That reduction matters because it shortens the pause between the user’s turn and the agent’s response.
Normalised Output for LLMs
Raw transcripts are rarely the final product. They become inputs for LLMs and APIs. That makes validation and normalisation part of STT quality.
Parrot applies Hindi focused validation and normalisation so outputs are more consistent before they enter downstream systems.
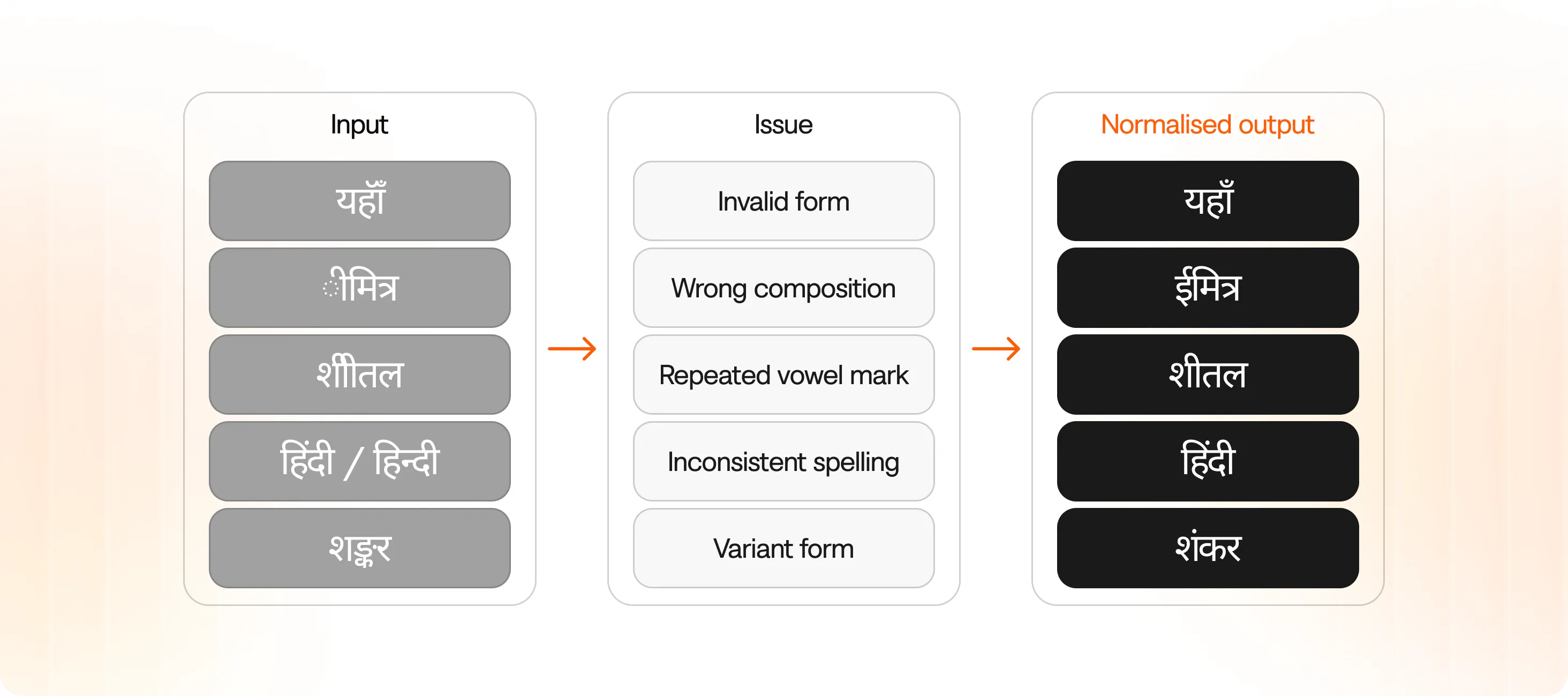
How Parrot Works: Custom STT Model, Hindi Tokenization, and Normalisation
Parrot is not just a single model swap. It is a production STT system with five layers:
Production data curation: Parrot has been trained on 60,000+ hours of Hindi speech data, including real call conditions, background noise, dialect variation, and operational vocabulary.
- Hindi aware tokenisation: Hindi tokenisation is designed around syllable-level units. This helps reduce Devanagari composition errors, represents Hindi word forms more consistently, and can reduce token load during inference.
- Low latency inference: The pipeline is tuned for short conversational turns, fast finalisation, and high-throughput usage across enterprise call volumes.
- Validation and normalisation: The validated and normalized transcript provides a clear conversational flow, reducing the likelihood of LLM hallucinations.
- Evaluation on practical conditions: Parrot is tested against public Hindi benchmark datasets and real-world call patterns, using normalised WER to measure the quality of the text that a voice agent stack actually consumes.
- Parrot was built by combining a custom STT model with production-focused data curation, streaming optimisations, and a normalisation layer tuned for Hindi speech.
Parrot STT Benchmarks: Accuracy, Latency, and Cost
Normalized WER
We evaluated Parrot across public STT benchmark datasets and real world audio conditions using normalised WER. Rather than relying only on curated, pre-cleaned audio from narrow sources, our evaluation is designed to reflect practical voice agent performance: variable call quality, accents, code-switching, and transcripts that need to be consumed by LLMs, and downstream APIs.
Normalised WER measures transcription quality after applying a consistent text-normalisation step across outputs, making it especially relevant for production voice agent systems where formatting, numbers, punctuation, and accuracy affect the agent’s next action.
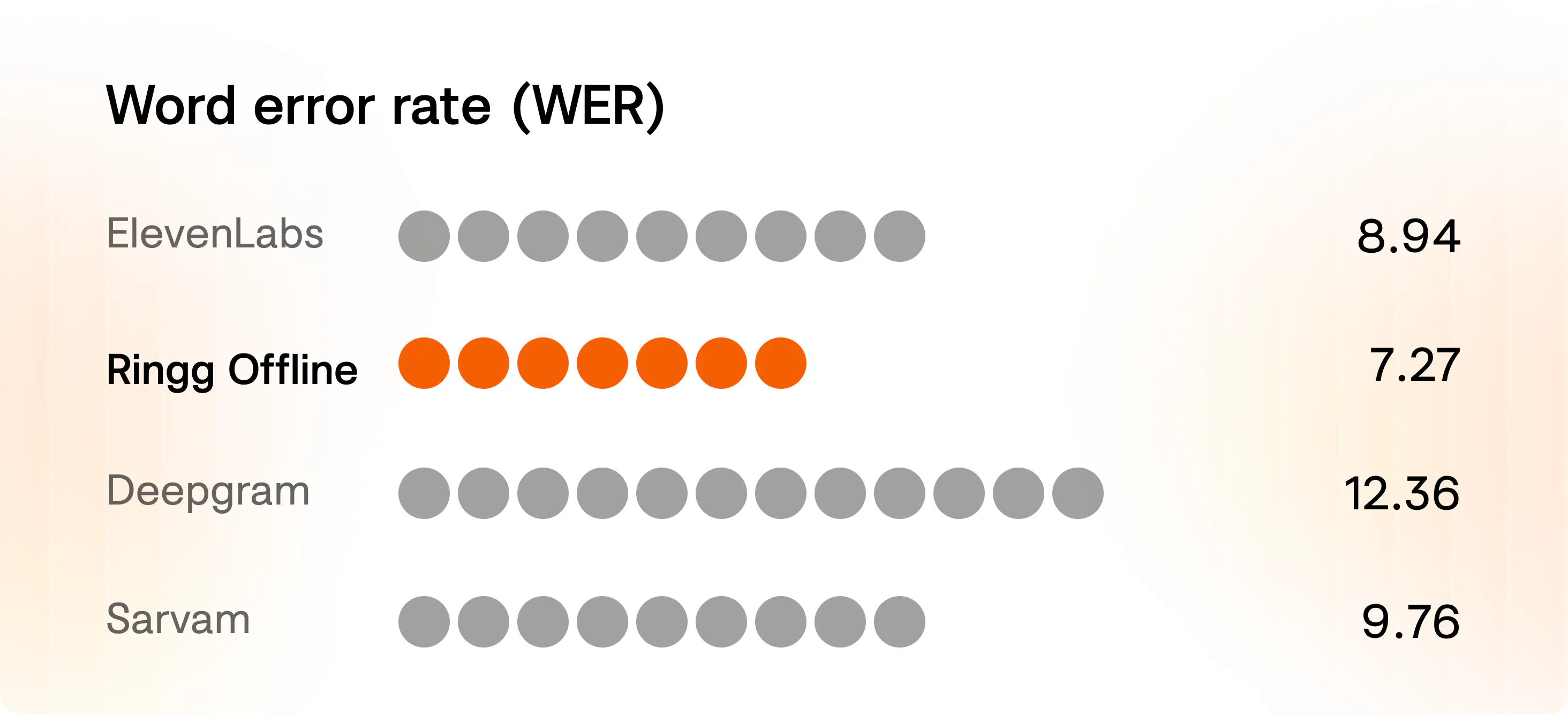
For Parrot adopters, this means fewer correction turns, fewer failed downstream actions, and cleaner transcripts for workflow automation.
Latency for Real-Time Voice Agents
Fast inference matters because STT sits before every response the agent gives. If transcription is slow, the LLM and TTS layers start late too.
Parrot is designed to reduce the time between user speech and usable text. Internal tests have measured compute latency near 60 ms under controlled conditions
Pricing Model Built for Voice AI
Many STT APIs charge based on audio sent for transcription. In voice-agent systems, that can include silence, interruptions, filler, retries, and audio that never becomes useful text. At scale, this overhead affects unit economics.
Parrot's pricing is designed around the transcript received, not simply the audio sent. The closer pricing maps to usable output, the easier it becomes to control STT cost as call volume grows.
To learn more about pricing, book a demo
Roadmap: What Parrot Will Support Next
Parrot is the first step in Ringg's STT roadmap. Upcoming areas of work include:
- Speaker diarization
- Broader language coverage
- Stronger noisy-call robustness
- Custom vocabulary for domain-specific terms
- Better handling of names, addresses, and alphanumeric identifiers
The long-term goal is to make the speech layer more reliable for every downstream action in a voice agent workflow.
Where Parrot STT Into Your Voice AI Stack
Parrot can sit anywhere speech becomes workflow input:
- Customer support agents that need to capture issue type, order IDs, and next actions
- Appointment and booking flows that depend on names, dates, locations, and slot availability
- Healthcare and insurance workflows where medicine names, policy numbers, and user details matter
- Financial or operational workflows where confirmations and identifiers must be transcribed cleanly
- QA and analytics systems that need structured transcripts for review, summaries, and intent analysis
You can try Parrot from the Ringg dashboard:
https://www.ringg.ai/dashboard/stt
Developers can also use the RinggLabs Python SDK:
https://pypi.org/project/ringglabs/
Product page:
TRY PARROT
Build real-time voice agents with Parrot
Explore Ringg AI's speech-to-text model for low-latency, production-ready voice-agent workflows.
Related blogs
View all blogs
Pricing & Reviews
Is Vapi AI Pricing Worth It in 2026? A Cost Breakdown
Analyze the layered and complex Vapi AI cost vs Ringg’s all-in-one pricing for predictable scaling.
10 Jun 2026 · 5 min read

Tool Comparisons
11 Best No-Code AI Voice Agents In 2026 (Rated and Reviewed)
Wondering which no-code AI voice agent is right for your business in 2026? Here are 11 leading platforms compared across various parameters to help you choose.
10 Jun 2026 · 19 min read

Voice AI Guides
What is Voice AI Agent? Definition, Features, Benefits, Usecases and Examples
Stop losing customers to long hold times. Discover how an AI voice agent transforms telephone support and scales your enterprise operations instantly.
07 Jul 2026 · 9 min read